In Part 3, we built out the API and learned how to access a database from inside of our Play application. In this post we will take a deeper look at concurrent requests, utilizing the asynchronous tools at our disposal to fix some concurrency bugs that were introduced in the last section.
As before, the source code for this tutorial series is available on github with the code specifically for this post here. Since the code builds on the previous post, you can grab the current state of the project (where part three finished) here.
Racing to failure
We will start this post by looking at a concurrency problem that exists in our current implementation of Ticket Overlords. When a user attempts to place an order, the following steps are performed:
- The JSON body is parsed into an
Ordercase class - The current amount of available tickets is queried
- An order is saved to database if enough tickets are available
- The response in converted to JSON
We can represent this graphically while tracking the state of our available tickets.
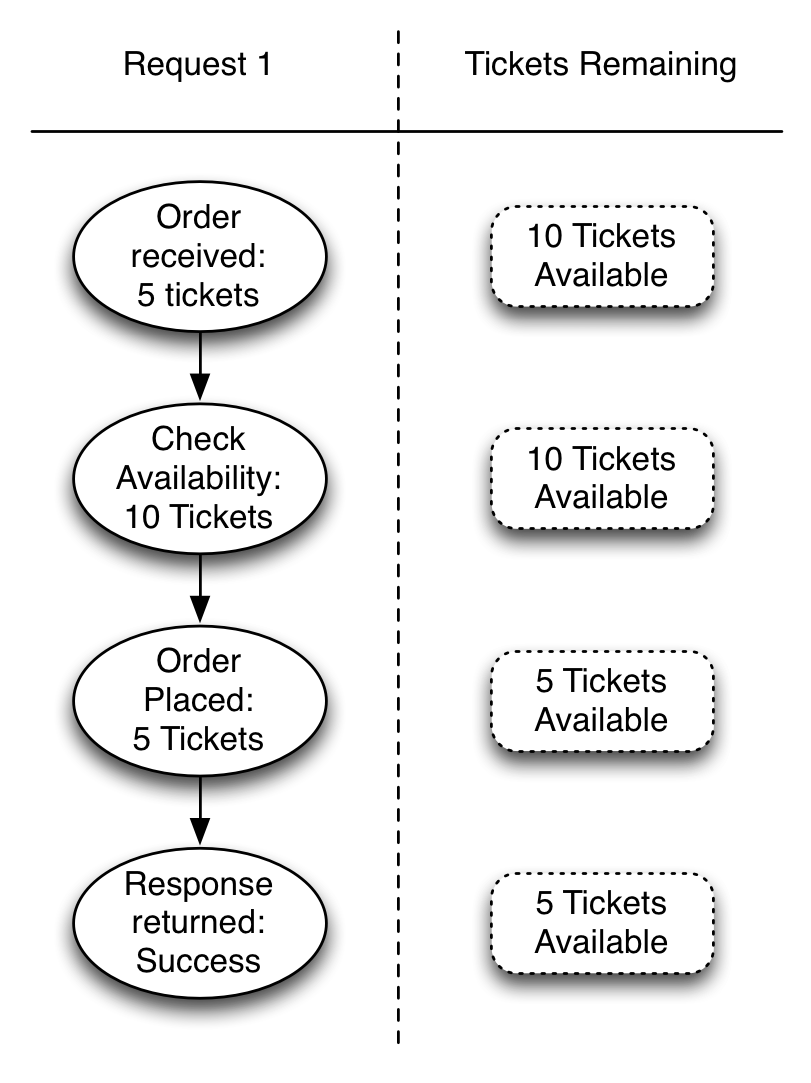
That diagram is a bit simplistic, as our server can easily be expected to handle multiple connections at the same time. Ignoring the asynchronous nature of the Slick calls to the database, we can illustrate two connections again to see what happens in a best case scenario.
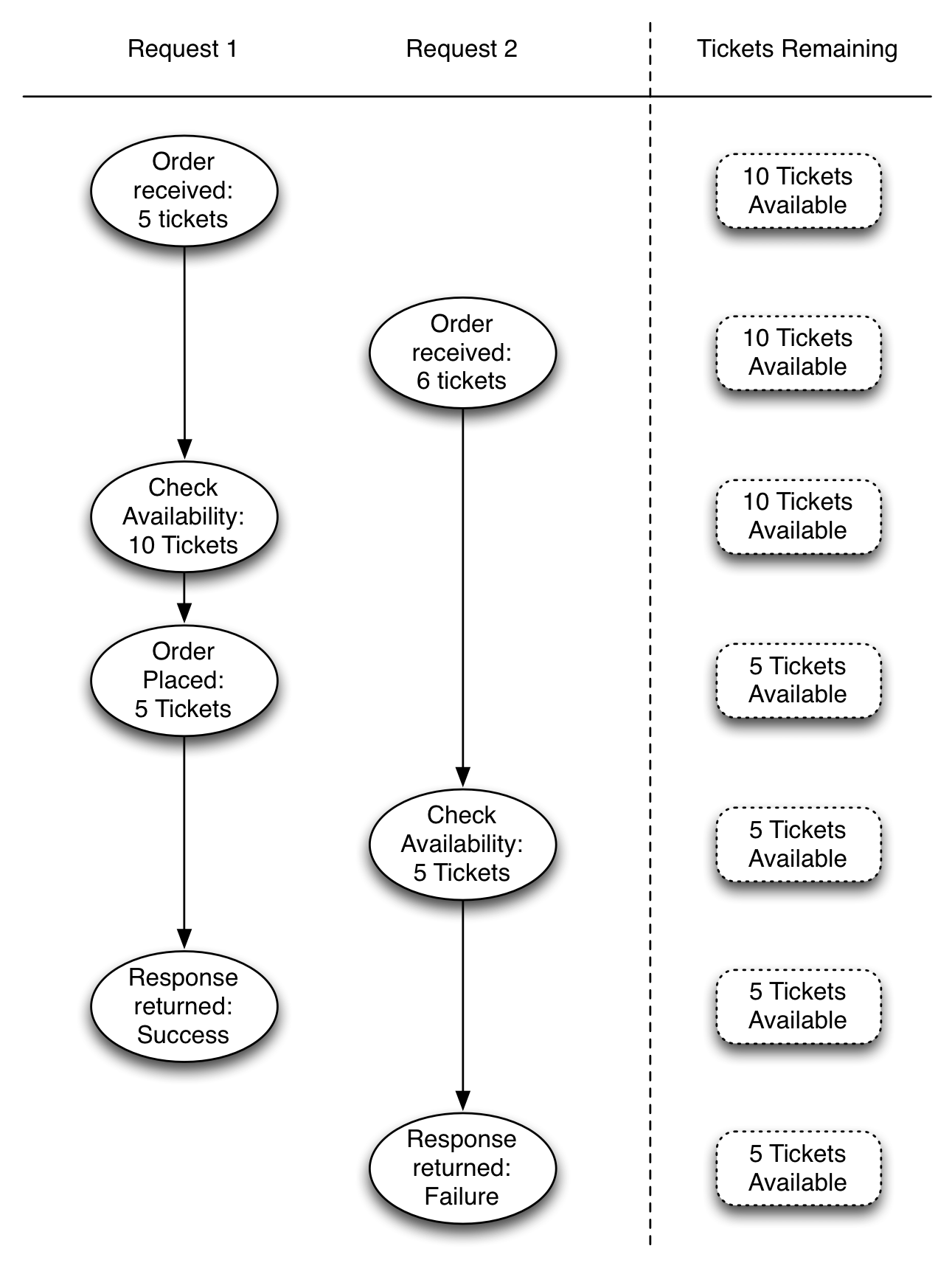
As before, the orders are processed as expected, with the first order removing five tickets from the available pool causing the second order to fail when it checks if there are six tickets still available for purchase. This is the best case scenario, but not the only possibility.
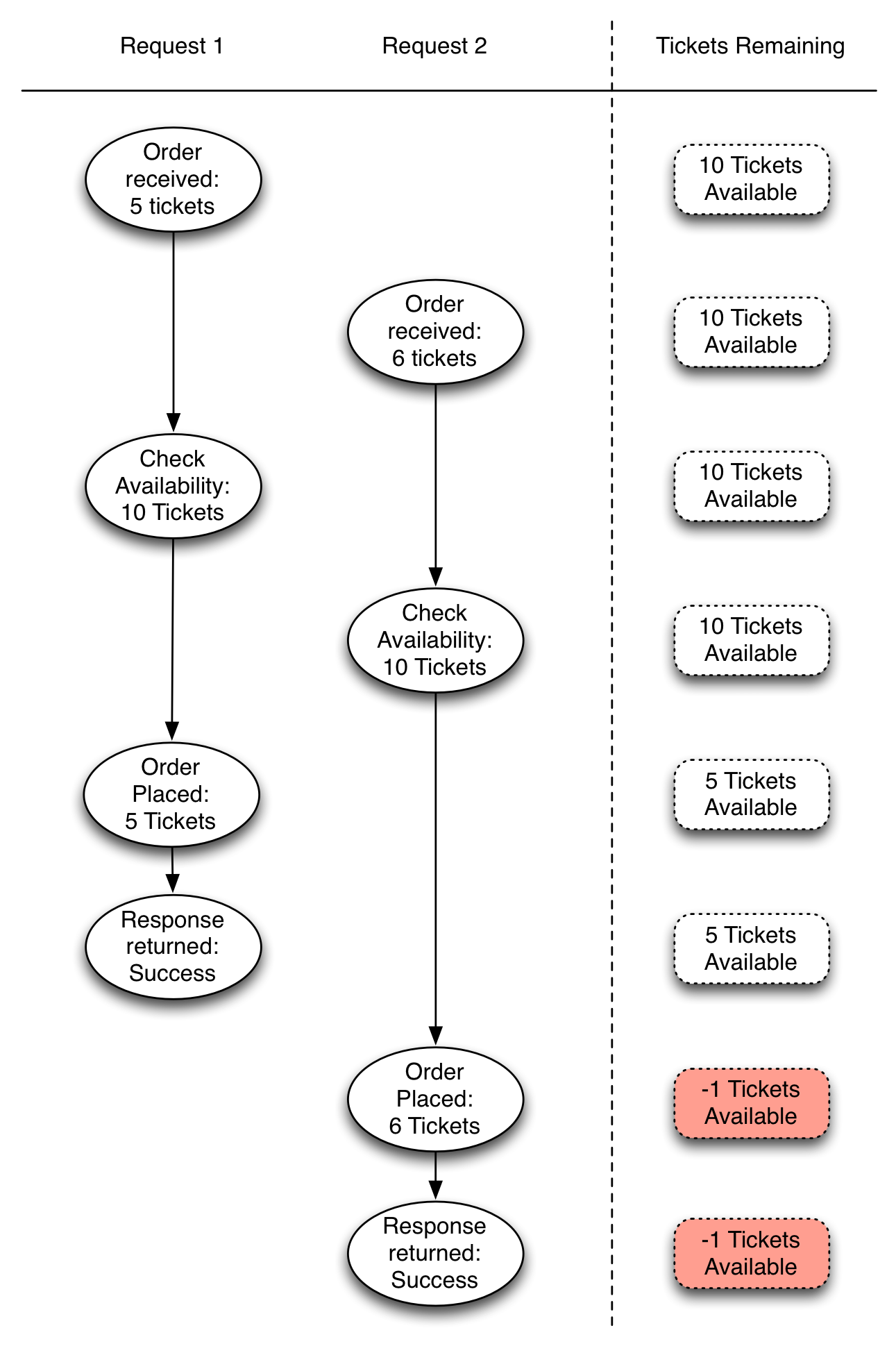
In this flow, we can see that the logic to check how many tickets were available ran in succession. This resulted in a race condition allowing tickets to be oversold. Since we are not running an airline, this is a problem. We have ignored the fact that our Slick requests are asynchronous only for simplicity in the diagram. In reality, the async nature amplifies this race condition.
Locking it down
You may be thinking “Gee, thanks for teaching me standard comp sci fundamentals, could we cover basic data structures next?” to which the answer is YES! Kind of. We are going to use actors as queues. Since the default mailbox of an actor functions as a queue, we can use this to ensure that the critical section consisting of Step 2 and Step 3 from before is performed atomically.
Start by creating a class named TicketIssuer in the
com.semisafe.ticketoverlords package that extends akka.actor.Actor.
package com.semisafe.ticketoverlords
import akka.actor.Actor
class TicketIssuer extends Actor {
def placeOrder(order: Order) {
// Get available quantity
// Compare to order amount
// place order if possible
// send completed order back to originator
// if not possible send a failure result
}
def receive = {
case order: Order => placeOrder(order)
}
}This is a fairly straight forward example of an actor skeleton. The receive
function only expects one type of message, an Order class indicating the order
to be placed. We can now fill out the placeOrder function. It will look very
familiar, as the logic is nearly identical to what is written in the Orders
controller.
Before we do this, we need to create a new case class
representing the error condition when no tickets are available.
case class InsufficientTicketsAvailable(
ticketBlockID: Long,
ticketsAvailable: Int) extends ThrowableNow for the rest of the placeOrder function.
// ... <snip> ...
import akka.actor.Status.{ Failure => ActorFailure }
import play.api.libs.concurrent.Execution.Implicits._
import scala.concurrent.Future
// ... <snip> ...
def placeOrder(order: Order) {
// This is important!!
val origin = sender
// Get available quantity as a Future
val availabilityResult = TicketBlock.availability(order.ticketBlockID)
availabilityResult.map { availability =>
// Compare to order amount
if (availability >= order.ticketQuantity) {
// place order
val createdOrderResult: Future[Order] = Order.create(order)
createdOrderResult.map { createdOrder =>
// send completed order back to originator
origin ! createdOrder
}
} else {
// if not possible send a failure result
val failureResponse = InsufficientTicketsAvailable(
order.ticketBlockID,
availability)
origin ! ActorFailure(failureResponse)
}
}
}The major difference between the original code from the controller and this
version is that we are not returning the responses directly. We are assuming
that an ask is utilized to call this actor and we either respond with
the expected Order that was created, or an akka.actor.Status.Failure
(renamed to ActorFailure to avoid ambiguity with the Failure associated with
a Try).
The fact that sender is reassigned to a local value of origin at the
beginning of placeOrder is also important. This is because sender is
actually sender(), a function. It is a common mistake to assume it is a value
that is safe to reference at any point. When origin is utilized to send the
createdOrder message back, it is actually two Futures deep. This means that
the value returned by sender() inside of createdOrderResult.map() is most
likely not the ActorRef that would be assigned when we saved the value into
origin.
We can now open up the Orders controller to make our changes that support the
new method of placing an order. We start by initializing an actor directly in
our controller.
import play.api.libs.concurrent.Akka
import play.api.Play.current
import com.semisafe.ticketoverlords.TicketIssuer
import akka.actor.Props
// ... <snip> ...
object Orders extends Controller {
val issuer = Akka.system.actorOf(
Props[TicketIssuer],
name = "ticketIssuer")
// ... <snip> ...Now that we know the actor will exist when we need it, we can replace the
existing create function in Orders with code that utilizes the
TicketIssuer actor. We could request an ActorSelection from the path
/user/ticketIssuer which is where our previously declared val ends up being
located, but since the ActorRef is stored locally, there is no need.
// ... <snip> ...
import akka.pattern.ask
import akka.util.Timeout
import scala.concurrent.duration._
// ... <snip> ...
def create = Action.async(parse.json) { request =>
val incomingBody = request.body.validate[Order]
incomingBody.fold(error => {
// Fold on error is the same as in the original version
val errorMessage = s"Invalid JSON: ${error}"
val response = ErrorResponse(
ErrorResponse.INVALID_JSON,
errorMessage)
Future.successful(BadRequest(Json.toJson(response)))
}, { order =>
implicit val timeout = Timeout(5.seconds)
val orderFuture = issuer ? order
// Convert successful future to Json
???
})
}We set a default timeout and proceed to send an ask message to the
TicketIssuer. An ask returns a Future[Any] as a result. This is what
people are complaining about when they say that Akka actors are not type safe.
We know orderFuture is not just a Future[Any], it is most definitely a
Future[Order]. We can force this with the mapTo method on the future.
val orderFuture = (issuer ? order).mapTo[Order]If something in our code changes later and for some reason the future can not be
cast to a Future[Order], the mapTo future becomes a failure and can be
handled by normal error recovery code.
While we are changing things, the value of 5 seconds is totally arbitrary and
probably too short. People used to camp out overnight for concert tickets, they
will wait at least 30 seconds on a website for an order to process. Open the
conf/application.conf and add the following lines to the end.
# User configurable timeout for ticket orders
ticketoverlords.timeouts.issuer=30In the Orders controller, we can remove the line with the hardcoded value and
replace it with logic to use the configuration value if present. Every
configurable value is an Option, so you will still need that arbitrary default
value.
val timeoutKey = "ticketoverlords.timeouts.issuer"
val configuredTimeout = current.configuration.getInt(timeoutKey)
val resolvedTimeout = configuredTimeout.getOrElse(5)
implicit val timeout = Timeout(resolvedTimeout.seconds)We are now ready to tackle the actual response from the actor. As before, we can
utilize map on the future to transform it from a Future[Order] to a
Future[Result].
// ... <snip> ...
// Convert successful future to Json
orderFuture.map { createdOrder =>
Ok(Json.toJson(SuccessResponse(createdOrder)))
}
// (Delete the "???" at this point if it is still there)This is looking good, but let’s be honest with each other. Not all futures are
sunshine and rainbows. Some result in a dystopian society where dogs and cats
live together and machines have enslaved us all. Our new robot overlords force
us to vacuum their apartments for them while they are at work, chanting over and
over “How do you like that now?” in disembodied robotic voices. Then there are
the futures that are really just caused by exceptions being thrown. We can
handle the latter case with the recover method.
// ... <snip> ...
import com.semisafe.ticketoverlords.InsufficientTicketsAvailable
import play.api.Logger
// ... <snip> ...
orderFuture.map { createdOrder =>
Ok(Json.toJson(SuccessResponse(createdOrder)))
}.recover({
case ita: InsufficientTicketsAvailable => {
val responseMessage =
"There are not enough tickets remaining to complete this order." +
s" Quantity Remaining: ${ita.ticketsAvailable}"
val response = ErrorResponse(
ErrorResponse.NOT_ENOUGH_TICKETS,
responseMessage)
BadRequest(Json.toJson(response))
}
case unexpected => {
Logger.error(
s"Unexpected error while placing an order: ${unexpected.toString}")
val response = ErrorResponse(
INTERNAL_SERVER_ERROR,
"An unexpected error occurred")
InternalServerError(Json.toJson(response))
}
})The recover method allows us to transform the Throwable content of the
failure into a different type of Future. In our case, there is the expected
failure when there are not enough tickets to process the order. There is also
a potential case where something unexpected occurs, which we will log and wrap
in a standard JSON response.
Increasing throughput
Our code no longer suffers from the same race condition during orders from concurrent requests, but it is still present in the async actions from the database access library. Although the race condition exists when two concurrent actions operate on the same ticket block, there is no problem if concurrent actions are operating on different ticket blocks.
Create a new class in the com.semisafe.ticketoverlords package named
TicketIssuerWorker. The base definition of this actor will differ slightly, as
we will add a constructor parameter for the ticket block ID.
package com.semisafe.ticketoverlords
import akka.actor.Actor
import akka.actor.Status.{ Failure => ActorFailure }
import play.api.libs.concurrent.Execution.Implicits._
class OrderRoutingException(message: String) extends Exception(message)
class TicketIssuerWorker(ticketBlockID: Long) extends Actor {
def placeOrder(order: Order) {
val origin = sender()
if (ticketBlockID != order.ticketBlockID) {
val msg = s"IssuerWorker #${ticketBlockID} recieved " +
s"an order for Ticket Block ${order.ticketBlockID}"
origin ! ActorFailure(new OrderRoutingException(msg))
} else {
val availResult = TicketBlock.availability(ticketBlockID)
availResult.map { availability =>
if (availability >= order.ticketQuantity) {
val createdOrder = Order.create(order)
createdOrder.map { origin ! _ }
} else {
val failureResponse = InsufficientTicketsAvailable(
order.ticketBlockID,
availability)
origin ! ActorFailure(failureResponse)
}
}
}
}
def receive = {
case order: Order => placeOrder(order)
}
}The logic inside of the TicketIssuerWorker is almost identical to the original
TicketIssuer, with extra logic that guarantees placing orders only for
the ticket block that was assigned at instantiation.
We now have the building blocks to add these workers in to our TicketIssuer
actor. We will start by creating a var member of TicketIssuer that is a
Map of ActorRefs and a utility function for adding a child actor worker for
a given ticket block ID. In general, we try to avoid the use of vars in scala,
but when inside of an actor, it can be acceptable within reason.
import akka.actor.{ ActorRef, Props }
// ... <snip> ...
class TicketIssuer extends Actor {
var workers = Map[Long, ActorRef]()
def createWorker(ticketBlockID: Long) {
if (!workers.contains(ticketBlockID)) {
val worker = context.actorOf(
Props(classOf[TicketIssuerWorker], ticketBlockID),
name = ticketBlockID.toString)
workers = workers + (ticketBlockID -> worker)
}
}
// ... <snip> ...This function checks to see if there is already a local reference to that ticket block. If the reference does not exist, a new actor is instantiated and has it’s reference added to the local mapping for retrieval later.
With this logic defined, we can now add a preStart method on our
TicketIssuer. The preStart method is called every time the actor is started
and restarted making it suitable for setting up the initial state of our actor.
override def preStart = {
val ticketBlocksResult = TicketBlock.list
for {
ticketBlocks <- ticketBlocksResult
block <- ticketBlocks
id <- block.id
} createWorker(id)
}To utilize our new TicketIssuerWorker classes, we need to replace the
placeOrder method in TicketIssuer.
def placeOrder(order: Order) {
val workerRef = workers.get(order.ticketBlockID)
workerRef.fold {
// We need a new type of error here if the ActorRef does
// not exist, or has not yet been initialized
???
} { worker =>
worker forward order
}
}The new placeOrder method extracts the ActorRef for the correct worker and
passes along the actual order to be placed. You will notice that instead of a
tell (!) or an ask (?), we use forward. This performs a tell operation
but passes along the original sender’s reference. This is what allows our
worker actors to reply to the originator of the request by using their local
sender result.
We still have an unhandled error condition, so we will create the class for that exception now.
case class TicketBlockUnavailable(
ticketBlockID: Long) extends ThrowableAnd update the placeOrder code one more time.
def placeOrder(order: Order) {
val workerRef = workers.get(order.ticketBlockID)
workerRef.fold {
sender ! ActorFailure(TicketBlockUnavailable(order.ticketBlockID))
} { worker =>
worker forward order
}
}To finish this up, the only change remaining is to add this new error condition
in the Orders controller, inside the recover block (right before the
unavailable case).
// ... <snip> ...
import com.semisafe.ticketoverlords.TicketBlockUnavailable
// ... <snip> ...
case tba: TicketBlockUnavailable => {
val responseMessage =
s"Ticket Block ${order.ticketBlockID} is not available."
val response = ErrorResponse(
ErrorResponse.TICKET_BLOCK_UNAVAILABLE,
responseMessage)
BadRequest(Json.toJson(response))
}
// ... <snip> ...This requires a new ErrorResponse value to be defined. Once again, any value
will work, the example code uses 1002.
Updating the worker pool
One thing you may have noticed is that the system will only create worker actors
when the TicketIssuer actor is started (or restarted). This means that we are
not be able to access or place an order on a new ticket block without restarting
the system, which is inconvenient.
We will create a case class named TicketBlockCreated and place it just above
the class definition for TicketIssuer.
case class TicketBlockCreated(ticketBlock: TicketBlock)We will also modify TicketIssuer’s receive function to accept a
TicketBlockCreated message using the contents as the argument to the
createWorker function we defined earlier.
def receive = {
case order: Order => placeOrder(order)
case TicketBlockCreated(t) => t.id.foreach(createWorker)
}Now we have a way to respond to signals after a new TicketBlock has been
created. We can update the create method of TicketBlock to send this
message. Since the TicketBlock object has no local reference to the issuer
ActorRef, we need to use the actorSelection method.
// ... <snip> ...
import akka.actor.ActorSelection
import play.libs.Akka
// ... <snip> ...
def create(newTicketBlock: TicketBlock): Future[TicketBlock] = {
val insertion = (table returning table.map(_.id)) += newTicketBlock
db.run(insertion).map { resultID =>
val createdBlock = newTicketBlock.copy(id = Option(resultID))
val issuer: ActorSelection =
Akka.system.actorSelection("/user/ticketIssuer")
issuer ! TicketBlockCreated(createdBlock)
createdBlock
}
}If your application is running, stop it. Now start it again. (If it was not
running, start it now). Before you do anything to interact with the application,
try creating a fresh ticket block with curl.
curl -w '\n' http://localhost:9000/tickets/blocks/ \
-H "Content-Type:application/json" \
-d '{"name":"VIP Admission","eventID":1,"productCode":"VIP0001", "price":975.00,"initialSize":1000,"saleStart":1420660800000,"saleEnd":1397746800000}'
{"result":"ok","response":{"id":2,"eventID":1,"name":"VIP Admission","productCode":"VIP0001","price":975.00,"initialSize":1000,"saleStart":1420660800000,"saleEnd":1397746800000}}Based on the response from curl, it appears to have been successful. We
received a good response back and the ticket block has an ID, but if we look in
the activator log window, it tells a different story.
[application-akka.actor.default-dispatcher-4]
[akka://application/user/ticketIssuer]
Message [com.semisafe.ticketoverlords.NewTicketBlock]
from Actor[akka://application/deadLetters]
to Actor[akka://application/user/ticketIssuer] was not delivered.
[1] dead letters encountered. This logging can be turned off or adjusted
with configuration settings 'akka.log-dead-letters'
and 'akka.log-dead-letters-during-shutdown'.This happened because we only instantiate the TicketIssuer actor inside of the
Orders controller, but since nothing has interacted with that object yet, none
of the member values have been instantiated, including our actor.
A solution for this is to encapsulate all references to the TicketIssuer
inside of it’s own companion object. While we are creating a companion object,
we will follow another best practice for actors, creating a props method.
A props method unifies how all actors are created instead of requiring
differing code depending on if the actor requires instantiation parameters or
not.
// ... <snip> ...
import play.api.libs.concurrent.Akka
import play.api.Play.current
// ... <snip> ...
object TicketIssuer {
def props = Props[TicketIssuer]
private val reference = Akka.system.actorOf(
TicketIssuer.props,
name = "ticketIssuer")
def getSelection = Akka.system.actorSelection("/user/ticketIssuer")
}This guarantees that our TicketIssuer actor will have been instantiated before
any other code calls it, while also removing the need for other code to know
where it resides (the /user/ticketIssuer part). We can replace the
getSelection call in TicketBlock and the local reference in Orders with
the following code.
val issuer = TicketIssuer.getSelectionA downside to this is that instantiating the actor is still on-demand the first time a code path is hit that requires access to the ticket blocks. Depending on how much is required for the actor to start (how many ticket blocks need to have workers created), there may be some delay in the actual response. We will cover the actual 100% correct and recommended way in a later post. This method is good enough for now.
The separation of dogma and state
In Scala, it is generally not advised to use a var when a val will suffice.
If you define one in eclipse, it even colors it red as a way of saying “You
probably should not be doing this”. That said, there are times when a var is
appropriate. We already saw this with our map of TicketIssuerWorker
references. In the current TicketIssuerWorker code, every time an order is
placed there is a database query to gather the amount of available tickets,
followed by a second database query to create the order. The async calls here
are the root of why we still have a race condition. Now that
TicketIssuerWorker is the canonical source for ordering tickets, we can
actually maintain the ticket count internally within the worker.
Inside of the TicketIssuerWorker class, but outside of any function
definition, move the availability query from placeOrder to preStart and
make an availablilty private var.
private var availability = 0
override def preStart = {
val availabilityFuture = TicketBlock.availability(ticketBlockID)
availabilityFuture.onSuccess {
case result => availability = result
}
}Modify the placeOrder method to decrement availability by the amount of
the order. Now that the availability Future has been moved to the preStart
method, every access to the availability value is queued and locked by the
actor’s receive path.
if (availability >= order.ticketQuantity) {
availability -= order.ticketQuantity
val createdOrder = Order.create(order)
createdOrder.map(origin ! _)
} else {
// ... <snip> ...This is a safe use for a var since it is being used to represent the internal
state of the actor and it is not accessible to anything externally. The fact
that there is only one single concurrent path accessing the var maintains
safety from concurrency issues.
We can do better than this
Our TicketIssuerWorker is functioning properly, but we can probably find a
safe way to get rid of the var while also having it return a more appropriate
message while it is starting up. Currently, if a request comes in after
preStart has run, but before the database call finishes, the response will
appear that the ticket block has sold out, as opposed to a more correct message
that it is currently unavailable.
We can do all of this through the use of the actor’s become functionality. Our
actor really has three possible states: initialization, normal operation and
sold out. We can define these as three separate Actor.Receive functions that
accept either the Order message or a new case class AddTickets for when
tickets are to be added to our ticket block. We will also factor out the routing
validation from placeOrder as each receive method will utilize this.
def validateRouting(requestedID: Long) = {
if (ticketBlockID != requestedID) {
val msg = s"IssuerWorker #${ticketBlockID} recieved " +
s"an order for Ticket Block ${requestedID}"
sender ! ActorFailure(new OrderRoutingException(msg))
false
} else {
true
}
}
case class AddTickets(quantity: Int)
def initializing: Actor.Receive = {
case AddTickets(availability) => {
context.become(normalOperation(availability))
}
case order: Order => {
if (validateRouting(order.ticketBlockID)) {
val failureResponse = TicketBlockUnavailable(
order.ticketBlockID)
sender ! ActorFailure(failureResponse)
}
}
}
def normalOperation(availability: Int): Actor.Receive = {
case AddTickets(newQuantity) => {
context.become(normalOperation(availability + newQuantity))
}
case order: Order => placeOrder(order, availability)
}
def soldOut: Actor.Receive = {
case AddTickets(availability) => {
context.become(normalOperation(availability))
}
case order: Order => {
if (validateRouting(order.ticketBlockID)) {
val failureResponse = InsufficientTicketsAvailable(
order.ticketBlockID, 0)
sender ! ActorFailure(failureResponse)
}
}
}
// This replaces the previous definition of receive
def receive = initializingNotice at the end, we have replaced the previous definition of receive with a
statement indicating that the actor begins with the initializing behavior. We
use the context.become() method to change behavior and communicate the current
availability value. The removes the need for the var, which can now be
removed.
We need to modify our placeOrder method one more time to account for this.
def placeOrder(order: Order, availability: Int) {
val origin = sender
if (validateRouting(order.ticketBlockID)) {
if (availability >= order.ticketQuantity) {
val newAvailability = availability - order.ticketQuantity
context.become(normalOperation(newAvailability))
val createdOrder = Order.create(order)
createdOrder.map(origin ! _)
} else {
val failureResponse = InsufficientTicketsAvailable(
order.ticketBlockID,
availability)
origin ! ActorFailure(failureResponse)
}
}
}And finally update our preStart method to safely pass the initial availability
to our actor.
override def preStart = {
val availabilityFuture = TicketBlock.availability(ticketBlockID)
availabilityFuture.onSuccess {
case result => self ! AddTickets(result)
}
}This give us a fully operational concurrency safe actor that manages an internal
state without the use of a var.
Until next time…
We now have a system that can safely handle many concurrent requests where each
ticket block is isolated from the other ones. We covered reading
configuration parameters from the conf files, handling failure cases in
Futures. We have also learned about handling asynchronous actions and managing
state with actors, which is good for the general overall performance of a Play
application.
In part 5, we will take a quick look at composing futures from multiple sources.